
Where Does AI Get Its Facts?
A Data-Driven Look at the Knowledge Behind Machine Intelligence
Artificial Intelligence may sound confident when it answers a question, but it doesn’t actually “know” anything in the human sense. What we call AI knowledge is really a reflection of the information it was trained on — a massive mosaic of books, research papers, websites, datasets, archives, and more.
Just like a student becomes wise by reading many sources, an AI model becomes informative by being exposed to many types of data. The difference? Instead of a few textbooks, AI ingests trillions of words and millions of documents.
So where does that information come from?
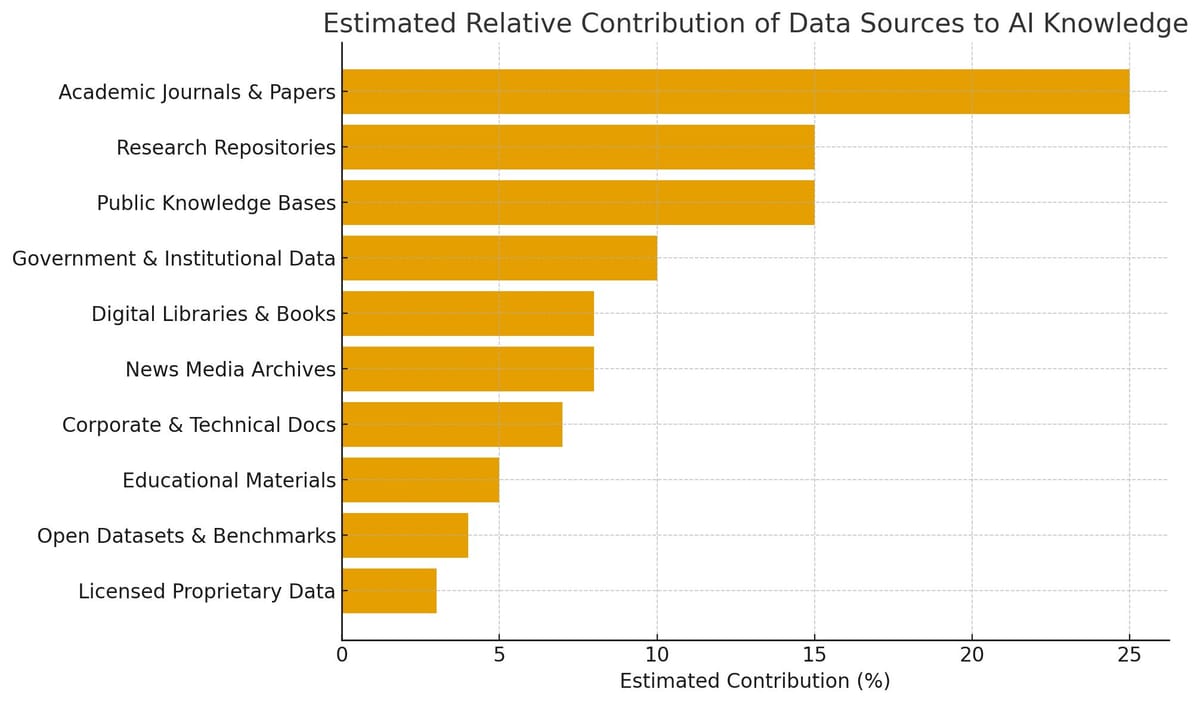
📚 The Building Blocks of AI Knowledge
Based on common training compositions from modern large language models, AI systems are typically fueled by a mix of verified, public, and licensed data sources:
| Source Type | Approx. Share | Why It Matters |
|---|---|---|
| Peer-reviewed journals & academic papers | 25% | High-credibility discoveries & scientific facts |
| Research repositories (arXiv, PubMed, etc.) | 15% | Cutting-edge findings before they appear in textbooks |
| Public knowledge bases (Wikipedia, Wikidata) | 15% | Structured, community-maintained general facts |
| Government & institutional datasets | 10% | Global statistics from trusted organizations (UN, World Bank) |
| Digital libraries & books | 8% | Historical, literary, and cultural depth |
| News archives | 8% | Real-world events, timelines, and human perspectives |
| Corporate & technical documentation | 7% | Industry standards, APIs, engineering knowledge |
| Educational resources | 5% | Tutorials, textbooks, course material |
| Open datasets & benchmarks | 4% | Data for training skills like math, coding, and logic |
| Licensed proprietary data | 3% | Protected data purchased to improve accuracy or reduce bias |
🧠 What This Means for AI Accuracy
AI isn’t a magical brain — it’s a reflection of its dataset. The quality, diversity, and balance of that dataset determine whether an AI is:
✅ Reliable or misleading
✅ Biased or neutral
✅ Helpful or harmful
For example:
- A model trained mostly on news could reflect media bias.
- A model trained mostly on academic papers might sound too technical.
- A model trained with no licensed data may miss modern or specialized knowledge.
That’s why responsible AI development involves data curation, filtering, and constant updating — not just code.
🔍 Why Transparency Matters
AI models are becoming part of everyday decision-making: medicine, law, education, finance, even public policy. When an AI gives an answer, the real question is:
“Where did this information actually come from?”
As AI evolves, the future of trust in technology won’t rely only on what AI says — but where its knowledge was sourced, who approved it, and how recent it is.
🚀 The Next Era of AI Data
We’re moving toward models trained not just on more data, but on better-verified, more ethically sourced, more transparent datasets — including:
- Live, real-time factual updating
- Openly audited training sources
- User-controlled knowledge overlays
- Bias-detection datasets built into training
In other words: AI won’t just answer questions — it will show its work.
🧩 Final Takeaway
AI doesn’t invent facts. It absorbs them — from libraries, labs, newsrooms, governments, and the internet — then learns patterns to respond like a human.
So the next time an AI answers a question, remember:
✅ It’s not speaking from intuition
✅ It’s speaking from the sum of its data
✅ And the quality of that data is the real superpower



